设计模式-模板
分区表和分库分表和读写分离
分区表
由于分区表在MySQL Server层为一个表,因此:
1、DDL操作需要锁定所有分区,导致所有分区上操作都被阻塞。
2、当表数据量较小时,分区表和非分区表性能相近,分区表效果有限。
3、当表数据量较大时,对分区表进行DDL或其他运维操作难度大风险高。
4、分区表使用较少,存在未知风险多,BUG多BUG多BUG多,MySQL社区版本免费,横向扩展成> 本低,分库分表实现简单且中间件完善。
5、当单台服务器性能无法满足时,对分区表进行分拆的成本较高,而分库分表能很容易实现横> 向分拆。
6、当分区表操作不当导致访问所有分区时,会导致严重的性能问题,而分库分表操作不当仅影> 响访问的表。
7、使用分库分表可以有效运维降低运维操作影响,对1亿数据量表做DDL操作需要谨慎评估,而> 对10万数据量表做DDL操作可以默认其很快完成。
8、使用分库分表可以有效减小宕机或其他故障影响,将数据分库分表到10套群集上,一套群集> 发生故障仅影响业务的一成。
分区表无法解决单库的性能瓶颈
分区表关联查询,很困难
不走分区健,将会导致所有分区性能下降
DDL操作风险大
分库分表
sharding-jdbc
独写分离
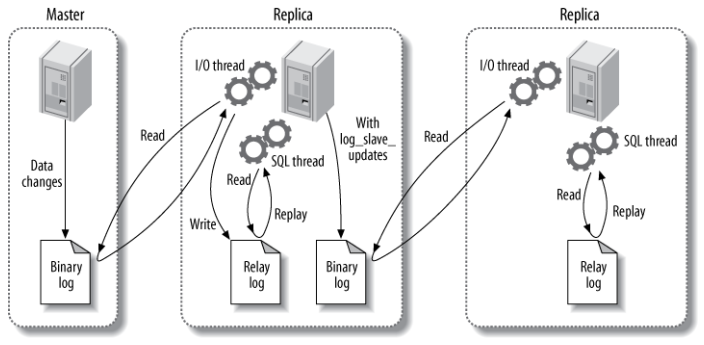
MYSQL双主,主从等
replication协议 的大数据量延迟很严重,需要特别注意。
设计模式-代理
设计模式-工厂
使用场景
屏蔽内部复杂,符合迪米特法则(最少知道原则)
原理
根据标识(string,emum),创建相关对象(一组实现相同接口对象)
招式
1 |
|
参考
mysql 分页和数据量
select id,title from collect limit 0,10;
select id,title from collect limit 1000,10;
select id,title from collect limit 90000,10;
select id from collect order by id limit 90000,10; -走主键索引
select id,title from collect where id>=(select id from collect order by id limit 90000,1) limit 10; -走主键索引
带查询条件
select id from collect where vtype=1 order by id limit 90000,10;
create idx_search(vtype,id)
select id ,title from collect where vtype=1 limit 90000,10;--慢如果对于有where 条件,又想走索引用limit的,必须设计一个索引,将where 放第一位,limit用到的主键放第2位,而且只能select 主键
最终办法 用IN 查询主键,会走索引
select * from collect where id in (9000,12,50,7000);