不要谈国外是怎么样,国情真心不一样喃。
不要谈什么经验换年龄,10年前EJB,weblogic,IBM大型机现在还在用吗?当然有些领域,估计还没来及学习,已经过时了。
不要谈转行,出去炒个瓜子都没别人有经验,你说你有互联网思维?你没平台,啥思维都没用。
不要谈转管理,技术专家,在大平台里面有一定概率可行。
咋办????
(1)一直学习(有家庭了杂事多,学习效率很低;一转头,脖子咔咔咔,鼻炎,脂肪肝,学习效率也没那么高。
(2)奉献你的青春,换公司后续给你的保障(找个有发展的大平台,猛干,后面要么是钱够了,要么是资历够了)。
(3)如果哪一天平台把你淘汰了,不要高不成低不就,找个工作磨着吧(靠吹,靠人脉),等到退休那一天。
建议?
尽可能做好上面3点吧。
再乐观一点,
财务规划好一点,
对家里面好一点。家里没矿,都是先苦再说甜。
Spring依赖注入控制反转
依赖注入与控制反转基本概念
依赖注入:对于spring而言,将自己置身于spring的立场上去看,当调用方需要某一个类的时候我就为你提供这个类的实例,就是说spring负责将被依赖的这个对象赋值给调用方,那么就相当于我为调用方注入了这样的一个实例。从这方面来看是依赖注入。
控制反转:对于调用方来说,通常情况下是我主动的去创建的,也就是对于这个对象而言我是控制方,我有他产生与否的权力,但是,现在变了,现在变为spring来创建对象的实例,而我被动的接受,从这一点上看,是控制反转。
避免使用方,NEW 调用对象
注入方式
1.field注入
2.构造器注入
(1).IOC容器启动会严格检查,构造函数为空的参数会报错,脱离IOC使用会无法注入属性。
(2).避免构造方法中使用属性,NPE异常
Java变量的初始化顺序为:静态变量或静态语句块–>实例变量或初始化语句块–>构造方法–>@Autowired3.setter注入
springboot 注入
1 |
|
1 | tom: |
@ConstructorBinding 这个注解,就标识这个类的参数优先通过带参数的构造器注入,如果没有带参数的构造器则再通过 setters 注入
不支持 @Component、@Bean、@Import 等方式创建 bean 的构造器参数绑定
@Autowired@Qualifier和@Resource
注入
@Autowired
spring的注解,默认按type(类型)注入
@Qualifier
spring的注解,按名字注入 一般当出现两个及以上bean时,不知道要注入哪个,作为@Autowired()的修饰用
@Primary
spring的注解,绑定在bean上,提高注入优先级(如果一个类型,有2个实现)
@Resource
(这个注解属于J2EE的),默认按name注入,可以通过name和type属性进行选择性注入
@Import(*.class)
spring的注解,注入类里所有实例化的bean
名称生成规则
1.在使用@Component、@Repository、@Service、@Controller等注解创建bean时,如果指定bean名称,
则是指定的名称.2.如果不指定bean名称,bean名称的默认规则是类名的首字母小写,如SysConfig - sysConfig,Tools - tools。
3.如果类名前两个或以上个字母都是大写,那么bean名称与类名一样,如RBACUserLog - RBACUserLog,RBACUser - RBACUser,RBACRole - RBACRole。
使用进阶
Autowired 修饰setter方法、普通方法、实例变量和构造器
https://blueblue233.github.io/blog/adf82bcd/
JAVA SPI 和Spring start
SPI
SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用
当服务的提供者提供了一种接口的实现之后,需要在classpath下的META-INF/services/目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类。当其他的程序需要这个服务的时候,就可以通过查找这个jar包(一般都是以jar包做依赖)的META-INF/services/中的配置文件,配置文件中有接口的具体实现类名,可以根据这个类名进行加载实例化,就可以使用该服务了。JDK中查找服务的实现的工具类是:java.util.ServiceLoader
缺点:
无法定制化,全加载,使用也是迭代形式获取
https://www.pdai.tech/md/java/advanced/java-advanced-spi.html
Spring Boot - 自定义Starter封装
在META-INF下创建spring.factory文件,需要@EnableAutoConfiguration配合使用
1 | org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ |
Properties->Configuration->Bean->AOP?
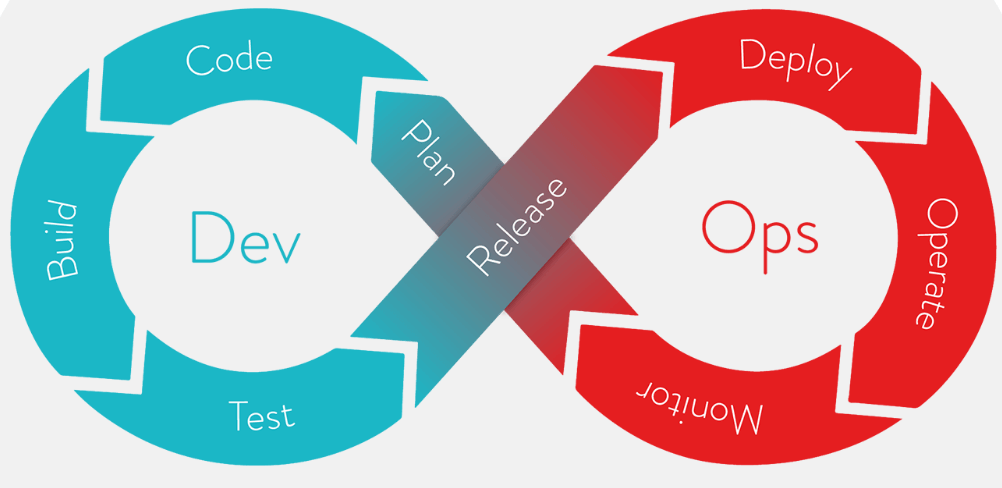
DevOps
基本概念
DevOps 一词的来自于 Development 和 Operations 的组合,突出重视软件开发人员和运维人员的沟通合作,通过自动化流程来使得软件构建、测试、发布更加快捷、频繁和可靠。
CI,Continuous Integration,为持续集成。即在代码构建过程中持续地进行代码的集成、构建、以及自动化测试等;有了 CI 工具,我们可以在代码提交的过程中通过单元测试等尽早地发现引入的错误;
CD,Continuous Deployment,为持续交付。在代码构建完毕后,可以方便地将新版本部署上线,这样有利于快速迭代并交付产品。Jenkins用于持续集成,而Gitlab CI / CD用于代码协作和版本控制
常见的开发模型
瀑布式开发 – 严格按照步骤,沉淀太多的文档,读写文档都存在极大成本,客户参与度低。
敏捷开发 – 先这样,后面再说,几哈操上去,利用禅道或者jira快速迭代,客户参与度高。(Scrum)
DevOps – 利用工具链加速开发,迭代,发布, 强调开发和运维之间的关系,降低时效成本。(CI/CD)
http://jartto.wang/2018/11/30/about-devops/
比较实际的工具链

JVM参数,定位,调优,工具
GC的注意事项
Java 具有四种强度不同的引用类型对垃圾回收的影响。
注意try括号的资源回收
https://www.pdai.tech/md/java/jvm/java-jvm-gc.html
OOM处理流程
-XX:+HeapDumpOutofMemoryEror
Eclipse Memory Analyzer(MAT) 分析Heap DUmp文件
https://www.jianshu.com/p/c34af977ade1
运行缓慢
jstack,jmap
https://www.pdai.tech/md/java/jvm/java-jvm-debug-tools-list.html
动态调试
Arthas
javaAgent(JVM的AOP) Java Instrumentation API来编写Agent
https://www.pdai.tech/md/java/jvm/java-jvm-agent-arthas.html
类加载
类字节码
Groovy, Scala, Koltin
魔数CAFEBABE
反编译class文件
javap -verbose -p *.class
类加载
启动类加载器: Bootstrap ClassLoader,负责加载存放在JDK\jre\lib(JDK代表JDK的安装目录,下同)下,或被-Xbootclasspath参数指定的路径中的,并且能被虚拟机识别的类库(如rt.jar,所有的java.*开头的类均被Bootstrap ClassLoader加载)。启动类加载器是无法被Java程序直接引用的。
扩展类加载器: Extension ClassLoader,该加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载JDK\jre\lib\ext目录中,或者由java.ext.dirs系统变量指定的路径中的所有类库(如javax.*开头的类),开发者可以直接使用扩展类加载器。
应用程序类加载器: Application ClassLoader,该类加载器由sun.misc.Launcher$AppClassLoader来实现,它负责加载用户类路径(ClassPath)所指定的类,开发者可以直接使用该类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
1 | public class loaderTest { |
自定义类加载器
只需要重写findClass,不要重写loadClass方法,因为这样容易破坏双亲委托模式(向上甩锅)
JVM-内存模型
JVM内存模型
–java8已经没有方法区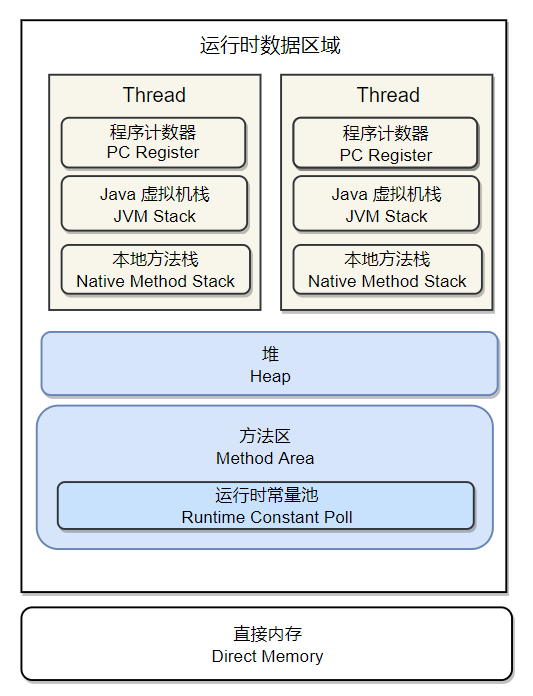
JVM概览
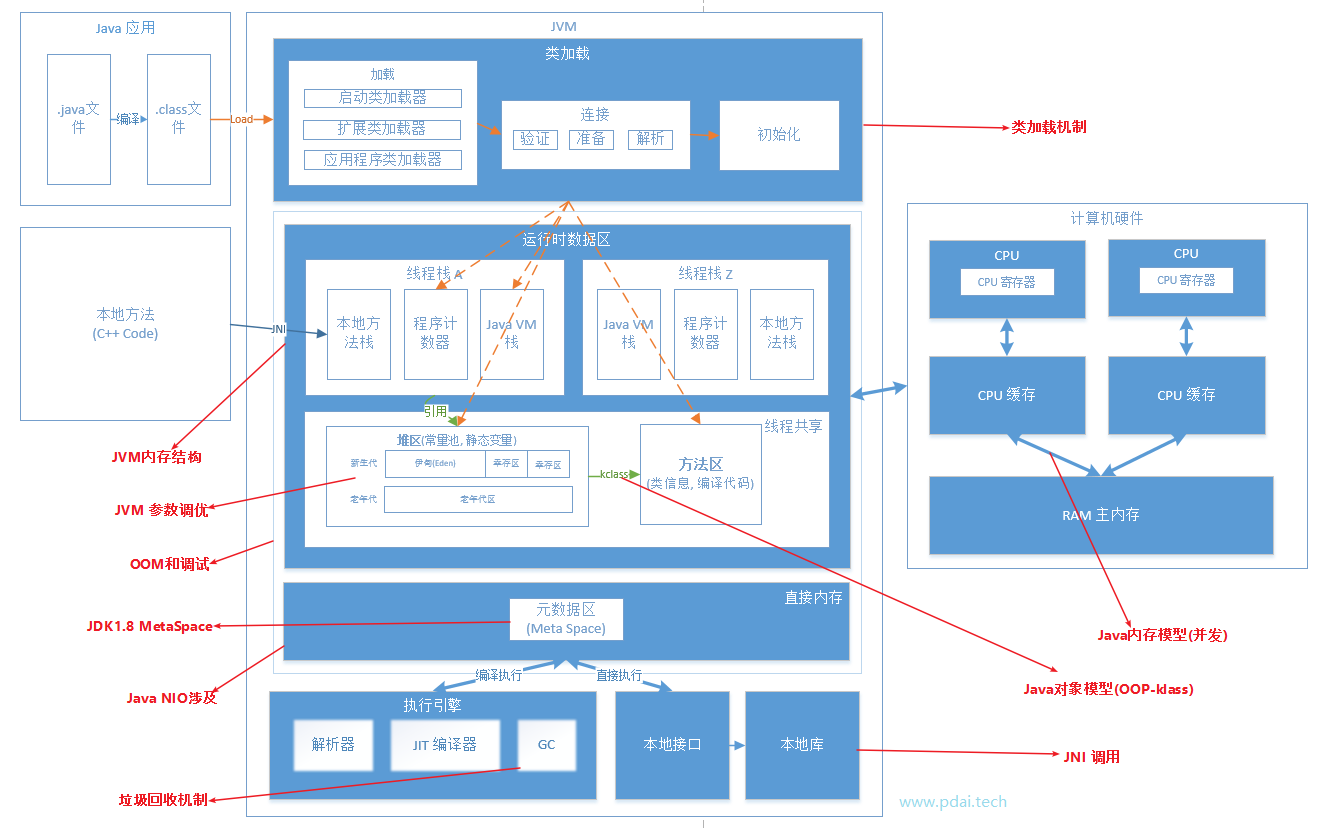
程序计数器
来记录程序的字节码执行位置
(1)程序计数器具有线程隔离性(2)程序计数器占用的内存空间非常小,可以忽略不计
(3)程序计数器是java虚拟机规范中唯一一个没有规定任何OutofMemeryError的区域
(4)程序执行的时候,程序计数器是有值的,其记录的是程序正在执行的字节码的地址
(5)执行native本地方法时,程序计数器的值为空。原因是native方法是java通过jni调用本地C/C++库来实现,非java字节码实现,所以无法统计
参考
https://doctording.github.io/sword_at_offer/content/java_jvm/jvm_class_load.html
ForkJoin
核心概念
核心思想: 分治算法
核心思想: work-stealing(工作窃取)算法WorkQueue双端队列
任务对象: ForkJoinTask (包括RecursiveTask、RecursiveAction 和 CountedCompleter)
执行Fork/Join任务的线程: ForkJoinWorkerThread
线程池: ForkJoinPool
Fork/Join 框架的执行流程
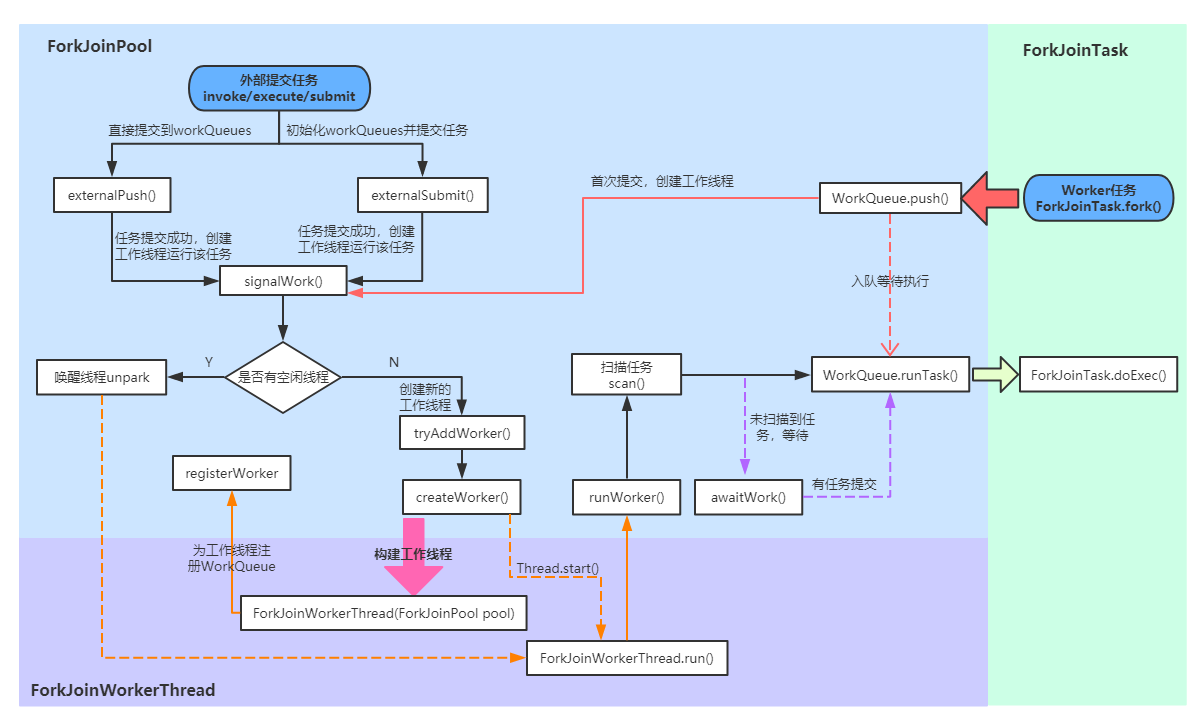
实际运用
注意顺序f1.fork(),f2.fork(), f2.join(),f1.join()
invokeAll(),不用太关系顺序
JDK源码中的运用:
特别注意IO密集型,容易导致全局ForkJoinPool.common阻塞。
Arrays.parallel**();
1 | default Stream<E> parallelStream() { |
1 | // 设置全局并行流并发线程数 |
https://www.pdai.tech/md/java/thread/java-thread-x-juc-executor-ForkJoinPool.html