1.二叉搜索树
容易倾斜;导致性能和链表类似。
2.红黑树
(最大好处,查找时间复杂度,是logn)
数学理论支撑 左旋,右旋 – 目的是红黑树,尽量平衡。 一个节点下面的2个节点的差,不会大于较小的那个节点的2倍差异。
新插入的节点都是RED,存在规则和情况,负责进行左旋或者右旋,改色。
3 2-3树
二三树允许在一个节点中可以有两个元素,等元素数量等于3个时候再进行调整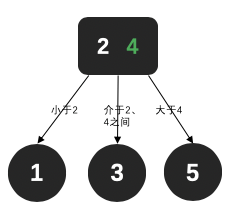
LSM-Tree
LSM-Tree全称是Log Structured Merge Tree,是一种分层,有序,面向磁盘的数据结构,其核心思想是充分了利用了,磁盘批量的顺序写要远比随机写性能高出很多
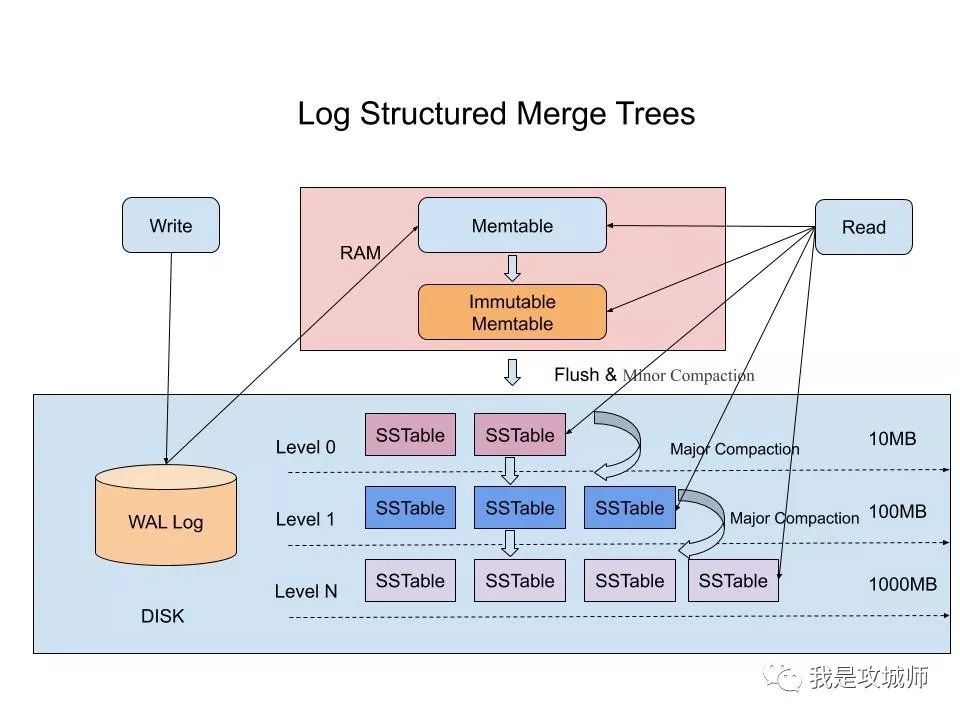
Hbase,Cassandra,Leveldb,RocksDB,MongoDB,TiDB,Kafka,ES均使用数据结构
B+Tree VS LSM-Tree
传统关系型数据采用的底层数据结构是B+树,那么同样是面向磁盘存储的数据结构LSM-Tree相比B+树有什么异同之处呢?
LSM-Tree的设计思路是,将数据拆分为几百M大小的Segments,并是顺序写入。
B+Tree则是将数据拆分为固定大小的Block或Page, 一般是4KB大小,和磁盘一个扇区的大小对应,Page是读写的最小单位。
在数据的更新和删除方面,B+Tree可以做到原地更新和删除,这种方式对数据库事务支持更加友好,因为一个key只会出现一个Page页里面,但由于LSM-Tree只能追加写,并且在L0层key的rang会重叠,所以对事务支持较弱,只能在Segment Compaction的时候进行真正地更新和删除。
因此LSM-Tree的优点是支持高吞吐的写(可认为是O(1)),这个特点在分布式系统上更为看重,当然针对读取普通的LSM-Tree结构,读取是O(N)的复杂度,在使用索引或者缓存优化后的也可以达到O(logN)的复杂度。
而B+tree的优点是支持高效的读(稳定的OlogN),但是在大规模的写请求下(复杂度O(LogN)),效率会变得比较低,因为随着insert的操作,为了维护B+树结构,节点会不断的分裂和合并。操作磁盘的随机读写概率会变大,故导致性能降低。
还有一点需要提到的是基于LSM-Tree分层存储能够做到写的高吞吐,带来的副作用是整个系统必须频繁的进行compaction,写入量越大,Compaction的过程越频繁。而compaction是一个compare & merge的过程,非常消耗CPU和存储IO,在高吞吐的写入情形下,大量的compaction操作占用大量系统资源,必然带来整个系统性能断崖式下跌,对应用系统产生巨大影响,当然我们可以禁用自动Major Compaction,在每天系统低峰期定期触发合并,来避免这个问题。
阿里为了优化这个问题,在X-DB引入了异构硬件设备FPGA来代替CPU完成compaction操作,使系统整体性能维持在高水位并避免抖动,是存储引擎得以服务业务苛刻要求的关键。