什么是布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
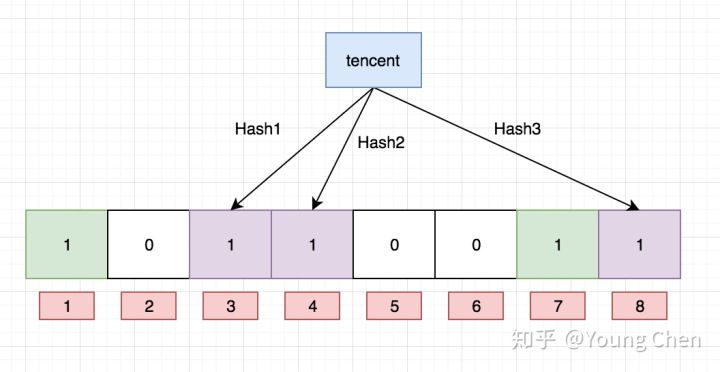
计数删除
目前我们知道布隆过滤器可以支持 add 和 isExist 操作,那么 delete 操作可以么,答案是不可以,例如上图中的 bit 位 4 被两个值共同覆盖的话,一旦你删除其中一个值例如 “tencent” 而将其置位 0,那么下次判断另一个值例如 “baidu” 是否存在的话,会直接返回 false,而实际上你并没有删除它。
如何解决这个问题,答案是计数删除。但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。这样的话,增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0。
bf超量
一是存储原始数据,当 bf 超过 1000 个元素后生成一个 2000 个元素的 bf,另一种是堆叠 bf (叫做 scalable bloomfilter),超过 1000 个元素后再生成一个新的 1000 容量的 bf,查询的时候查多个
BitSet
public void test(){
BitSet set = new BitSet(10); //10 bits set
//set() 设为true
set.set(0);
set.set(1);
set.set(5);
System.out.println(set); // 应该是列出值为true的那些位的坐标!
// 8 bit >> 1 byte, 就是说截取8位,转成byte。 就是0010 0011 >>
System.out.println(Arrays.toString(set.toByteArray()));
// 64 bit >> 1 long
System.out.println(Arrays.toString(set.toLongArray()));
}生成随机数0~1亿范围按照大小排序
HashSet
new BitSet(100000000),内存不过是 100000000/8 B ≈ 12 MB!
每得到一个随机数,就将相应的位设为true即可,bs.set(num)